Implement the new service
Finalize the iteration
The new microservice will manage its own database defined by the data group identified in step 2 (Booking and Ticket).
The other data used by the Booking functionality are good candidates for the next iteration.
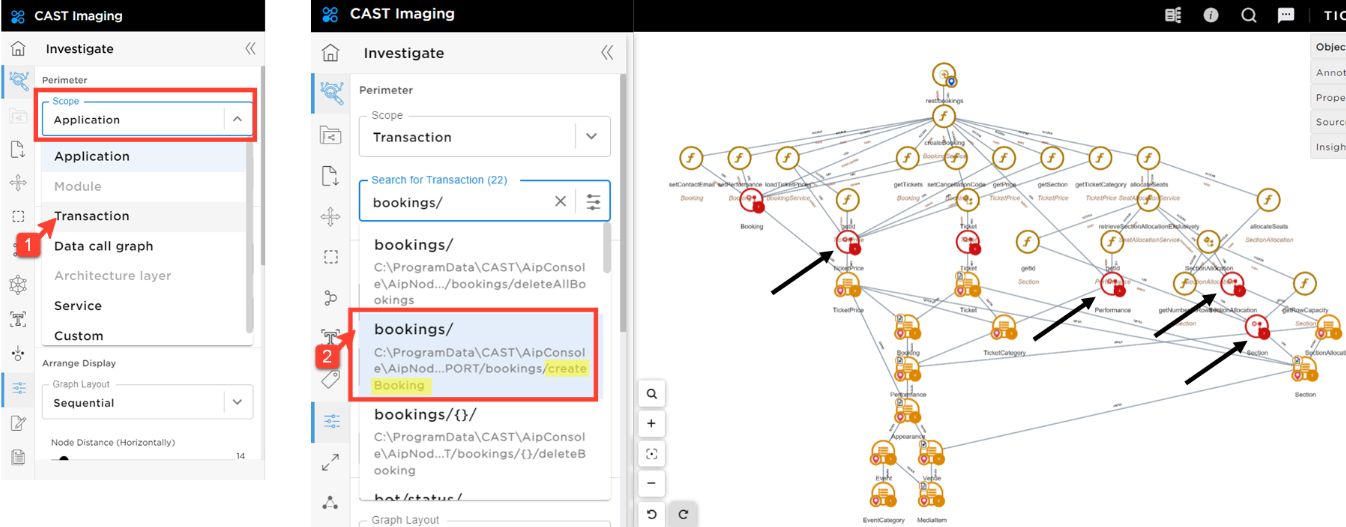
Choose the scope Transactions on the left hand menu to display the transaction named bookings/.
Based on the transaction call graph, you can immediately pinpoint other data that the new microservice will need to get access to: TicketPrice, Performance, Section, Section Allocation.
The iteration is finalized: you have identified good candidates for the first wave of microservice transformation.
During the implementation
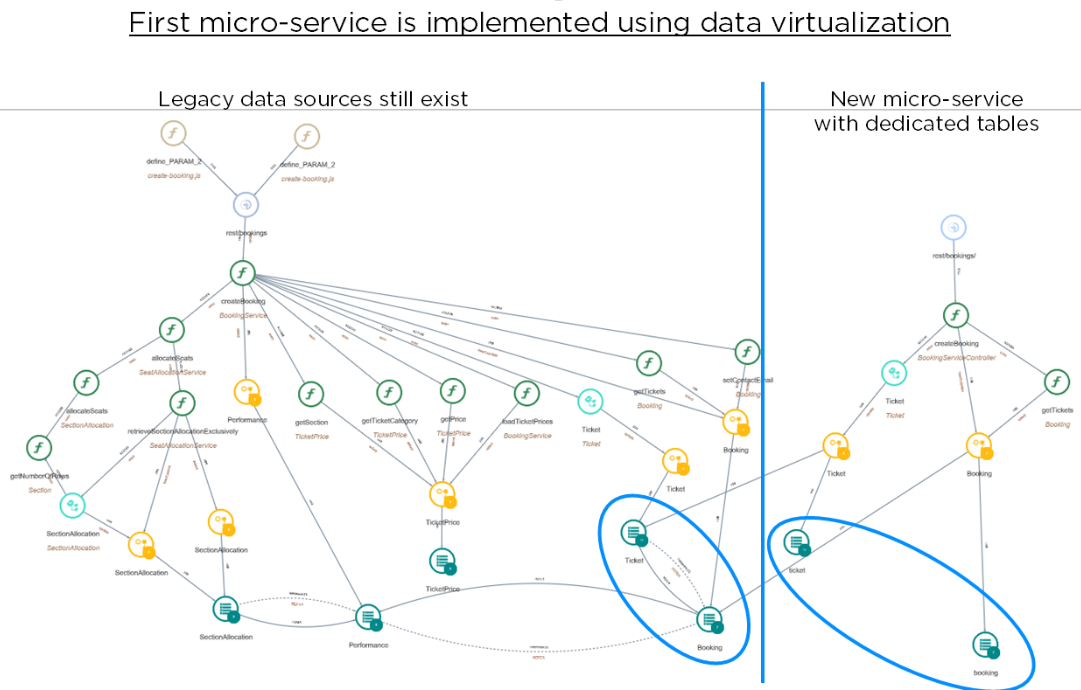
While rewriting the features in a new microservice, there might not be a clear separation between database objects. In that case, the new service will have to implement data accesses through: - new API/services or - data replication or - data virtualization or - static data as configuration.
For the new service identified for Booking, we will use the data virtualization mechanism. It provides a layer of abstraction above the physical implementation of data, to simplify the querying logic, while the application operations are redirected to the new microservice tables.
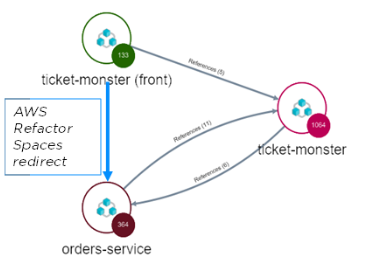
Redirect with AWS Refactor Spaces
Once the new service is written, we will use AWS Refactor Spaces to redirect the front-end calls to the new microservice.
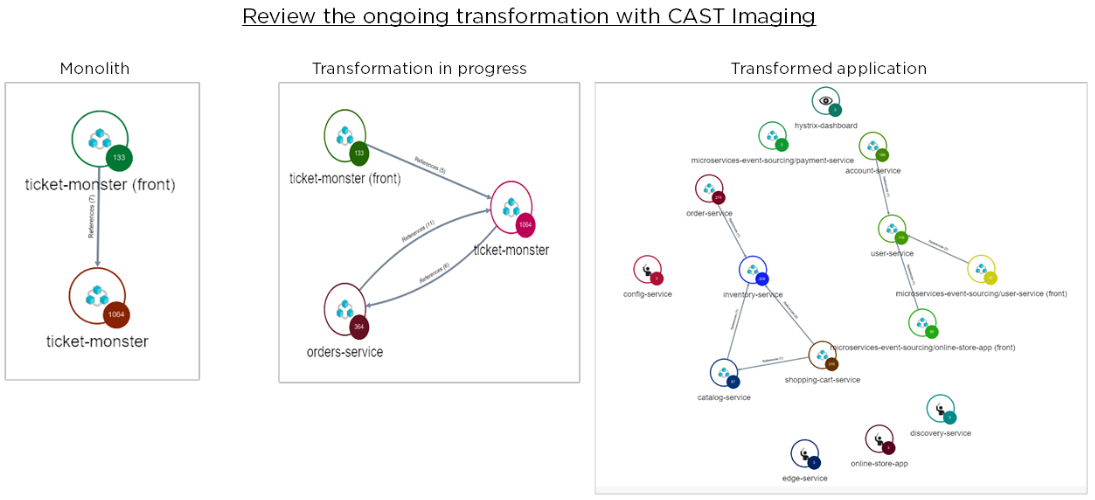
Review the ongoing transformation
CAST Imaging supports the application transformation, with coexistence of the legacy code with the new service (Strangler Fig Pattern), allowing to gradually control that new services are correctly isolated, data sources properly accessed and better identify the candidates for the next iterations, until the legacy code can be either decommissioned or be transformed in a micro-service as well.
Connect CAST Imaging to the application repository to update the application knowledge base and visualize new services but also deprecated functions.