Discover the architecture
Objective: With the goal to transform the monolithic application Ticket Monster to micro-services, we need first discover the architecture of the application to understand the technologies involved and adherences between the application layers, specifically the data layer which will be the starting point to determine a micro-service candidate.
The Ticket Monster application
Select the application Ticket Monster and investigate the application at the Level 5 perspective:
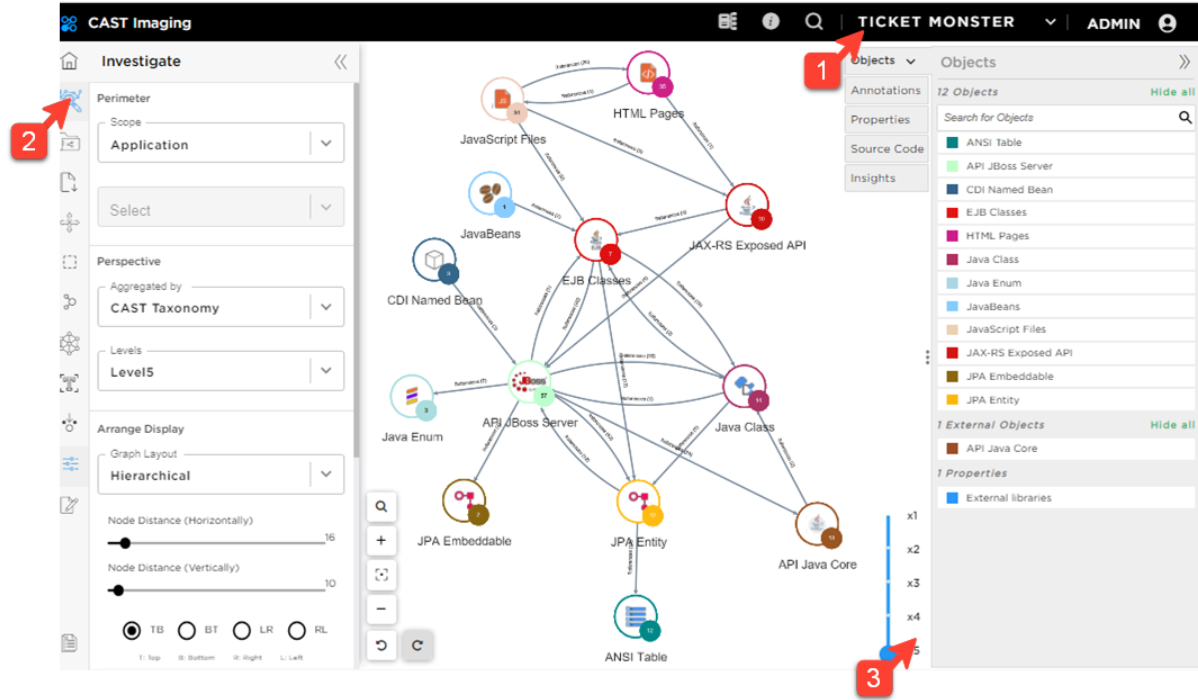
Ticket Monster is a monolithic Java/Web/MySQL application (the node name for MySQL is ANSI Table) with a JAX-RS API. The data layer is composed of 12 tables, accessed only through 12 JPA Entities.
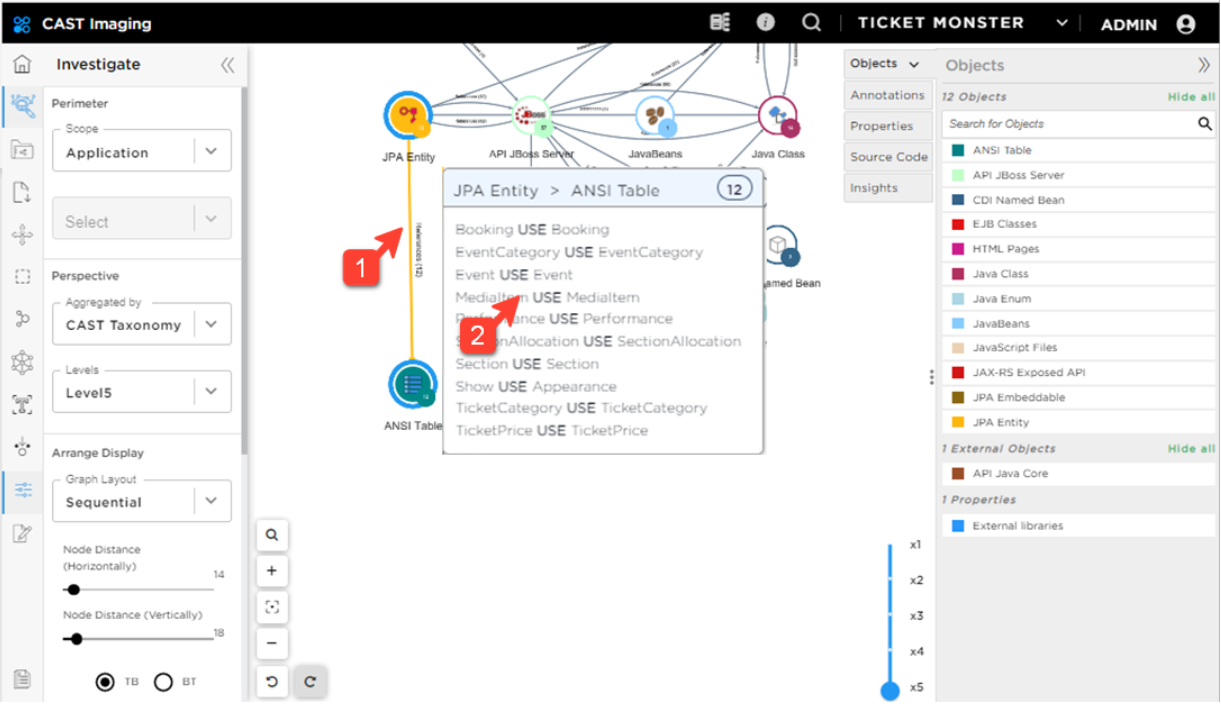
Double-click on the link between JPA Entity and ANSI Table to visualize the links between those nodes.
You see that the data access is properly designed with a single JPA Entity attached to a single table.
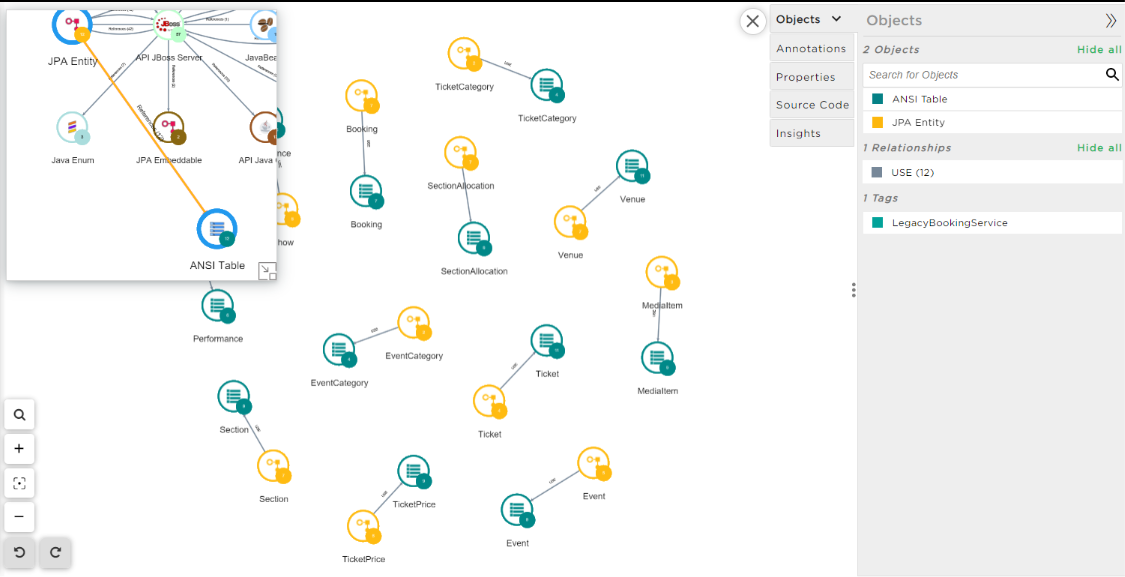
The decoupling journey starts
Let’s start the by choosing the best micro-service candidate for the iteration. We need to identify the adherences between the data sources based on foreign keys.
Click on the node ANSI Table to visualize all tables and their dependencies.
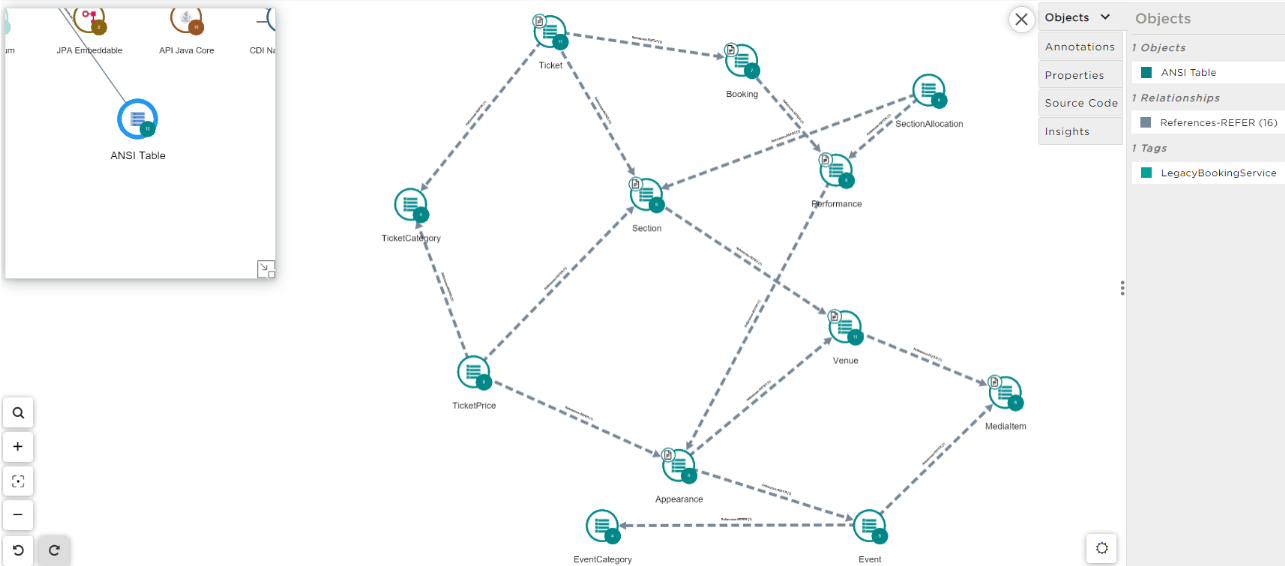
You can observe that tables are quite dependent on each other, so we will have to categorize the data groups, that is tables that will need to be together in the target microservice database.
Now, we have to identify the relations between data sources and transactions to better understand the adherence to the implementation layer and the tables utilization.